一、对读取源码的认识
1.1 带着问题去看源码
一开始拿到这套代码的时候,兴高采烈地去看,发现,有点难懂。
1.2 修改源代码,提高可读性
- 源代码中有部分代码有注释,但这不足以我去学习,因此,需要将注释补全。【注意:加上
JsDoc规范,这样能更清楚每个函数负责的是什么职责】
其实,在补全注释的过程,也就是你理解代码的过程,你的注释写对了,也就证明你看懂了这段代码是做什么的。
- 源代码中是
cmd语法,不能直接在浏览器中运行,需要编译,这也太麻烦了。所以,我们可以将cmd语法改为es6语法,便于代码在浏览器执行。
// cmd
var xxx = require("")
module.exports = xx
// 改为es6
import xx from 'nnn'
export xxx
注意:如果要在浏览器中运用es6的语法,那么在用script标签引入某文件的时候,必须添加type: module
<script type="module" src="main.js"></script>
- 有些代码结构看起来较复杂,比如三目运算符中嵌套三目运算。下面的例子,一看就有点懵了
// patch.js
var insertNode = maps[move.item.key]
? maps[move.item.key] : (typeof move.item === 'object')
? move.item.render() : document.createTextNode(move.item);
// 复杂的三目嵌套修改为简单的if...else结构
if (maps[move.item.key]) {
insertNode = maps[move.item.key]
} else if (typeof move.item === 'object') {
insertNode = move.item.render()
} else {
insertNode = document.createTextNode(move.item)
}
二、看看代码流程
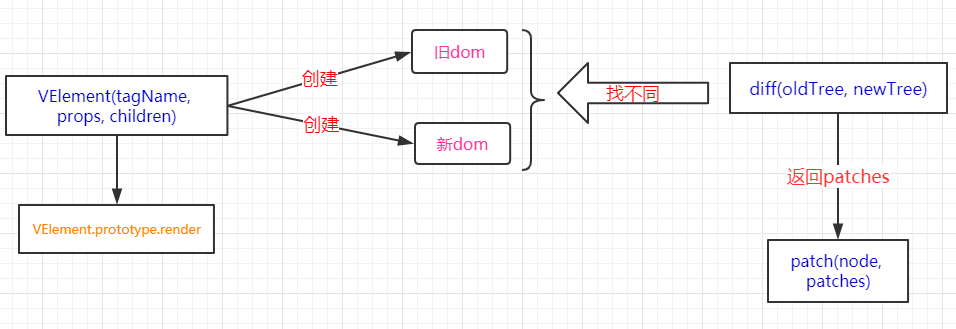
整个源码有三大核心板块,分别是:
VElement:创建虚拟DOM,每个虚拟DOM都有一个render方法(核心方法)diff:比较新旧虚拟DOM,找出两棵树有什么不同,并记录到一个对象中。patch:根据diff返回的结果,将真正的差异运用到真正的DOM树中
三、讲讲虚拟DOM
3.1 、虚拟DOM发展
我们都知道,原生的 DOM 操作十分耗性能,操作起来也十分麻烦,兼容性也要注意,所以jQuery就出来了。
jQuery 强大的选择器及高度封装的 API,使得 DOM 操作非常简单。但技术是发展的,MVVM 出现了。
比如 angularjs,vue.js,使用数据双向绑定,让我们脱离了对 DOM 的操作,开发效率大大提升,但大量的事件绑定使得在复杂的场景中出现了性能问题。
后来 ReactJs 出现了,既保证了开发效率有保证了性能,其中让HTML代码和JS代码混合的 虚拟 DOM 以及 diff 算法起了很大的作用。
3.2 虚拟DOM核心
虚拟的DOM的核心思想是:对复杂的文档 DOM 结构,提供一种方便的工具(开发效率),进行最小化地 DOM 操作(性能)
3.3 先看看虚拟DOM究竟是什么
这是html结构 - div有 4 个直系子节点
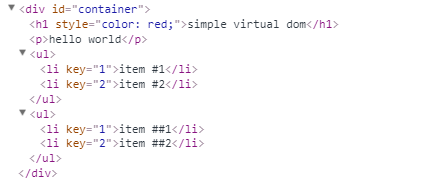
转化为虚拟DOM后,则是,可看到 children 里有 4 个 VElement(虚拟DOM元素)

可以看到,虚拟 DOM 其实就是一个 js 对象,主要有以下属性
children- 子节点集合count- 子节点数key- 提高性能的关键属性值props- 属性值tagName- 标签名
大家都知道,直接操作 js 对象绝对比操作 DOM 快,所以,既然直接操作 DOM 那么耗性能那么麻烦,那么我们就将 真实 DOM 转化为虚拟 DOM,对真实 DOM 的所有操作先在虚拟 DOM 上执行(包括增加、删除、移动、替换节点),以下是创建虚拟DOM的代码:
/**
* 虚拟DOM
* @param {string} tagName 标签名
* @param {object} props 属性对象
* @param {array} children 子DOM列表
* @return {VElement}
* @constructor
*/
var VElement = function(tagName, props, children) {
// 保证只能通过如下方式调用:new VElement
if (!(this instanceof VElement)) {
return new VElement(tagName, props, children);
}
// 可以通过只传递tagName和children参数
// 参数prop的可选处理,如果第二个参数传的是数组,证明不需要props
if (util.isArray(props)) {
children = props;
props = {};
}
//设置虚拟dom的相关属性
this.tagName = tagName;
this.props = props || {};
this.children = children || [];
// void 666 表示 undefined
this.key = props ? props.key : void 666;
// 后代元素的数量(包括文本节点)
var count = 0;
util.each(this.children, function(child, i) {
if (child instanceof VElement) {
// 若子元素是VElment对象,则证明有count属性,直接加上即可
count += child.count;
} else {
// 不然,则是文本节点
children[i] = '' + child;
}
// 加上此次遍历的元素
count++;
});
this.count = count;
}
整个构造函数做了4件事情:
VElement对象类型的判断:其实就是无new操作的实现,这与jQuery的无new操作的 本质是一样的,都是把new的过程放在了构造函数内部来处理。- 参数
prop的可选处理:如果第二个参数传的是数组,证明不需要props - 虚拟
DOM属性的相关设定:这个不多说【注意的是void 666,其实就是undefined】 - 对后代元素的处理:分了两类 - 要么是
String类型,表示子元素是文本,没有后代元素;要么是VElement对象,表示是虚拟DOM对象,有后代元素
3.4 再来看看VElement的render方法
/**
* 根据虚拟DOM创建真实DOM
* 具体思路:根据虚拟DOM节点的属性和子节点递归地构建出真实的DOM树
* @return {Element}
*/
VElement.prototype.render = function() {
//创建标签
var el = document.createElement(this.tagName);
//设置标签的属性
var props = this.props;
for (var propName in props) {
var propValue = props[propName]
util.setAttr(el, propName, propValue);
}
// 依次创建子节点的标签
util.each(this.children, function(child) {
// 如果子节点仍然为velement,则递归的创建子节点,否则直接创建文本类型节点
var childEl =
(child instanceof VElement) ?
child.render() :
document.createTextNode(child)
// 添加子节点
el.appendChild(childEl);
});
return el;
}
render 方法的本质:还是操作 DOM,这个函数就做了三件事:
- 创建元素
- 设置元素属性
- 添加子节点 - 文本节点或者元素节点
四、diff 算法
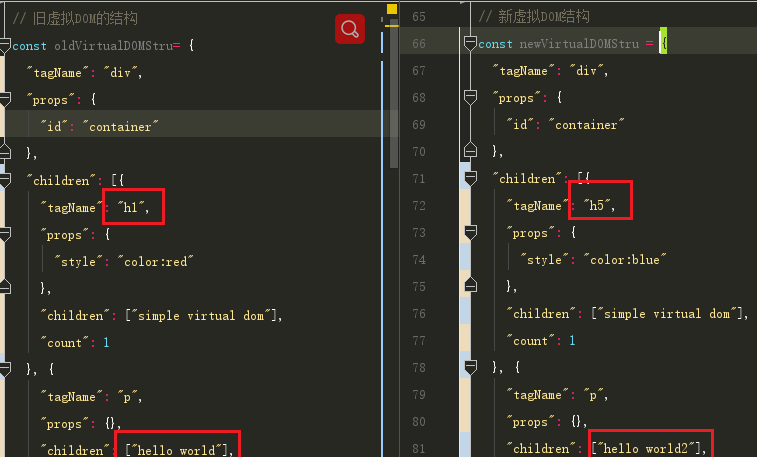
在研究 diff 算法之前,我先通过 JSON.stringify() 将新旧虚拟DOM的结构 console.log到控制台中,并将其值存储到 .answer.js文件中,便于分析。
4.1 diff算法三大策略
- 策略一:Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。 ====》
tree diff - 策略二:拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。====》
component diff - 策略三:对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。 ====》
element diff
4.2 tree diff - 深度优先遍历 - 比较两棵虚拟DOM树的差异
传统 diff 算法通过循环递归对节点进行依次对比,效率低下,算法复杂度达到 O(n^3),其中 n 是树中节点的总数。如果要展示 1000 个节点,就要依次执行上十亿次的比较。
但是在前端当中,很少会跨越层级地移动 DOM 元素。所以 Virtual DOM 只会对同一个层级的元素进行对比!【同一个层级指:同一个父节点的所有子节点】,如下图所示:
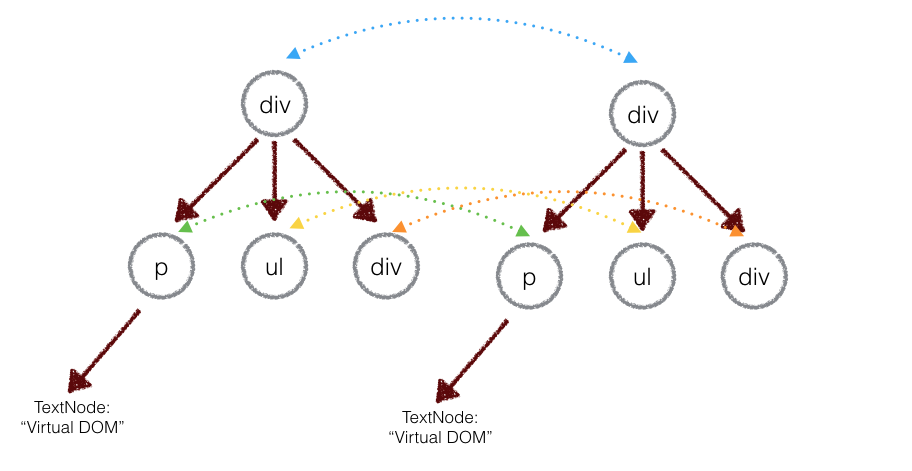
看看下面代码:
/**
* 避免了diff算法的复杂性,对同级别节点进行比较的常用方法是深度优先遍历
* @param {Object} oldTree - 旧DOM树
* @param {Object} newTree - 新DOM树
* @return
*/
function diff(oldTree, newTree) {
// 节点的遍历顺序
var index = 0;
// 在遍历过程中记录节点的差异
var patches = {};
// 深度优先遍历两棵树
dfsWalk(oldTree, newTree, index, patches);
return patches;
}
在实际操作中,我们只需要调用diff函数即可,而函数返回的是一个patch对象,这个对象就是记录两棵树差异的对象。
{
"1": [{
"type": 0,
"node": {
"tagName": "h5",
"props": {
"style": "color:blue"
},
"children": ["simple virtual dom"],
"count": 1
}
}],
"4": [{
"type": 3,
"content": "hello world2"
}],
"5": [{
"type": 1,
"moves": [{
"index": 2,
"item": {
"tagName": "li",
"props": {
"key": 3
},
"children": ["item #3"],
"key": 3,
"count": 1
},
"type": 1
}]
}],
"10": [{
"type": 1,
"moves": [{
"index": 1,
"type": 0
}]
}]
}
4.3 element diff - 差异类型
看到上面一大段的json数据结构,或许会有点懵。其实上面就已经提前告诉我们有那4中差异类型。
先看看,这是新旧 DOM 结构:
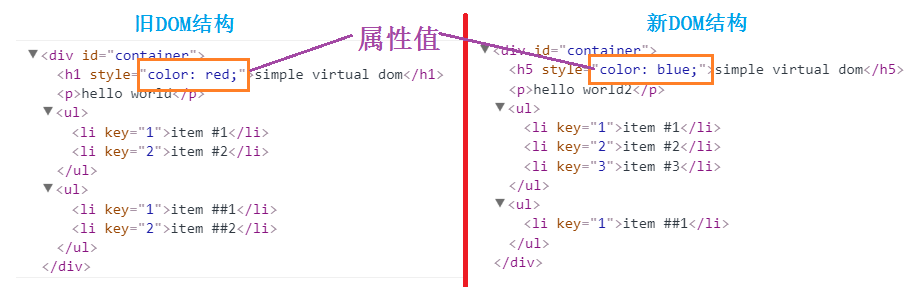
这是新旧虚拟DOM结构转化为树形结构 - 属性值的变化没有在下图展示,而是在上图展示了【具体虚拟DOM结构可查看 .answer.js 文件】
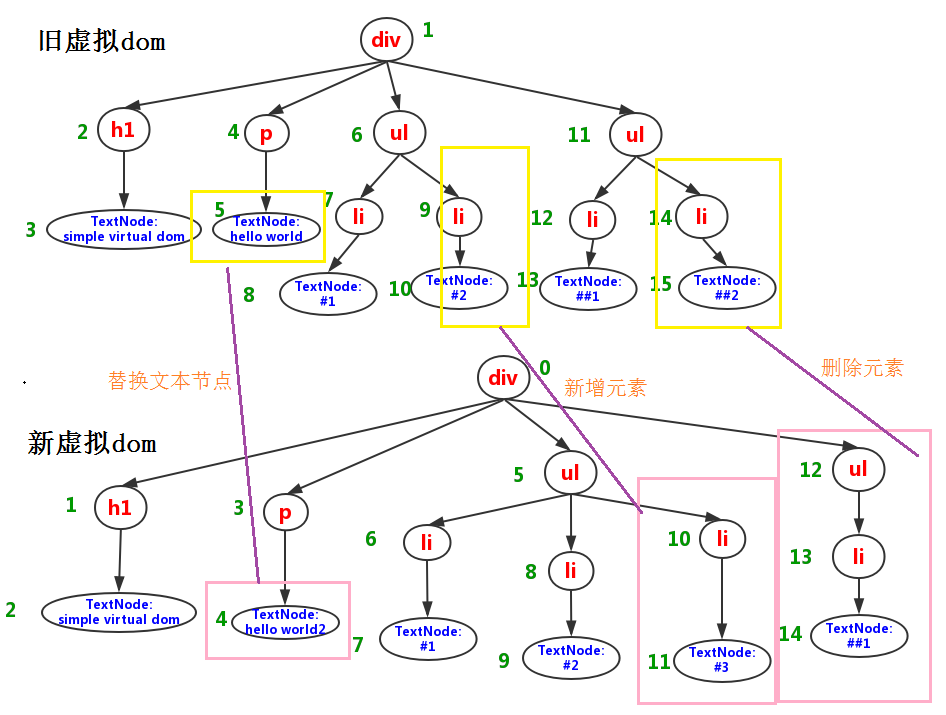
总的来说,diff 算法就有4种类型:
REPLACE- 0 - 替换原来的节点REORDER- 1 - 移动、删除、新增子节点PROPS- 2 - 修改节点的属性TEXT- 3 - 修改文本节点内容
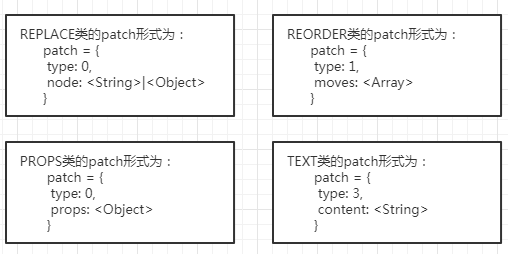
上图也就可以解析diff返回的json对象的每一项代表的是什么意思了!取“5”为例子
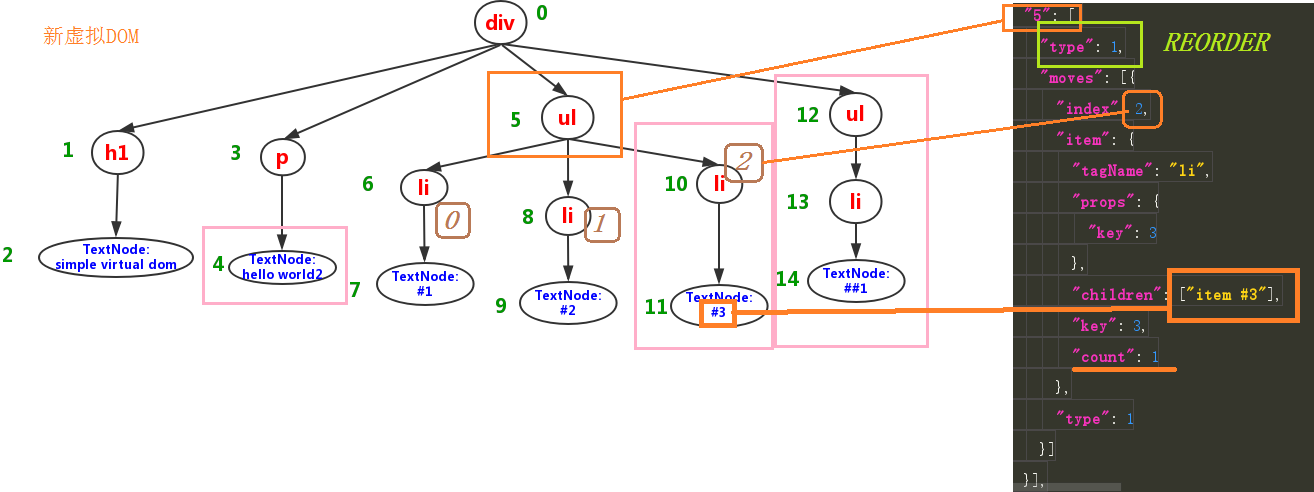
patch[5] = []中的5表示这个节点在整棵虚拟DOM树上存在的位置type = 1表示这个节点的差异类型为REORDER,其实这里就是新增了一个li节点moves属性表示的就是对节点进行什么操作index的值表示在基于整棵树去计算的第5个节点ul的子节点的基础上去数数,到第2个位置,新增一个li元素。count表示这个新增的li元素有多少个子节点,这里是1个
4.4 diff算法的优化 - key值
在使用 react 的时候,每当使用 array.map()这个函数,就要为元素添加 key 值,否则就会有警告。就只是按照要求去添加key值,但不是很懂为什么要添加。
在看了这个源码后,自己对 key 值有了一些理解。
4.5 如果出现了 DOM 节点跨层级的移动操作,diff 会有怎样的表现
比如:A 节点(包括其子节点)整个被移动到 D 节点下
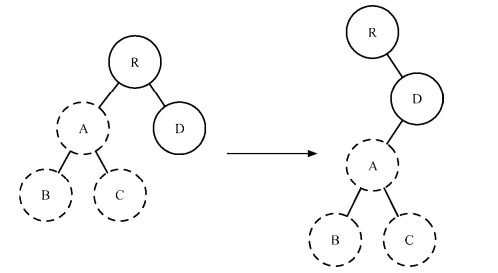
React只会简单地考虑同层级节点的位置变换,而对于不同层级的节点,只有创建和删除操作。- 当根节点发现子节点中
A消失,直接销毁A;当D发现多了一个子节点A,则则会创建新的A(包括子节点)作为其子节点 - 综述:
diff的执行情况:create A → create B → create C → delete A
五、patch
patch 将 tree diff 计算出来的 DOM 差异队列更新到真实的 DOM 节点上,最终让浏览器能够渲染出更新的数据。