- 参考资料:
- 《Node.js权威指南》 第 5 章 使用 Buffer 类处理二进制数据
一、创建Buffer对象
1.1 3中创建Buffer对象的方法
- 方法1:只需将缓存区大小 ( 以字节为单位) 指定为构造函数的参数:
new Buffer(size)

- 方法2:直接使用一个数组来初始化缓存区:
new Buffer(array)

- 方法3:使用一个字符串来初始化缓存区:
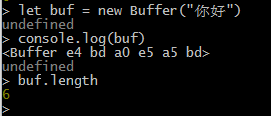
new Buffer(string, [encoding])【默认utf8】

1.2 length属性
- 被创建的
Buffer 对象有一个 length 属性,值为缓存区大小
1.3 buffer.fill ()
- 使用
Buffer 对象的 fill 方法来初始化缓存区中的所有内容:buffer.fill (value , [ offset ] , [end] )
value:必选,需要被写入的数值offset:可选,指定从第几个字节开始写入被指定的数值,默认为0【即:从缓冲区的起始位置写入】end:可选,指定将数值一直写入到第几字节处,默认值为Buffer对象的大小【即:书写到缓存区底部】
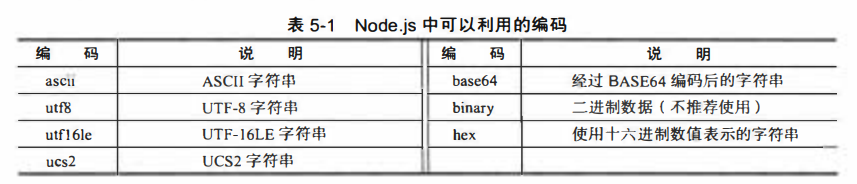
1.4 Node.js中可使用的编码
二、字符串的长度与缓存区的长度
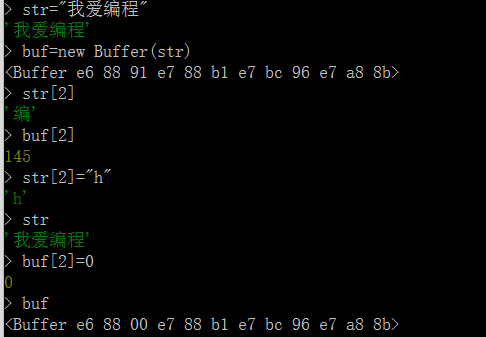
- 在
Node.js 中,一个字符串的长度与根据该字符串所创建的缓存区的长度并不相同。
- 计算字符串的长度:以文字作为一个单位
- 计算缓存区的长度:以字节作为一个单位
Buffer对象创建后,可被修改- 只具有
slice() 方法【Buffer 对象的 slice 方法并不是复制缓存区中的数据,而是与该数据共享内存区域,因此,如果修改使用slice方法取出的数据,则缓存区中保存的数据也将被修改】
三、Buffer 对象与字符串对象之间的转换
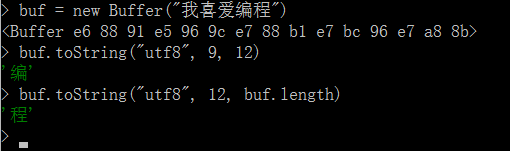
3.1 toString()
buffer.toString([encoding], [start], [end]):返回经转化后的字符串
encoding:可选,指定Buffer对象中保存的文字编码格式,默认utf8start:可选,指定被转换数据的起始位置【以字节为单位】end:可选,指定被转换数据的终止位置【以字节为单位】
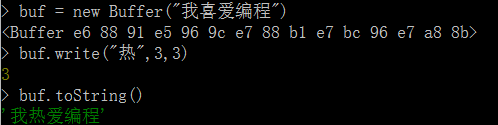
3.2 write()
buffer.write(string, [offset], [length], [encoding]):向已创建的 Buffer 对象中写入字符串
string:必选,写入的字符串offset 和 length:可选,指定字符串转换为字节数据后的写入位置
- 字节数据的书写位置从第
1 + offset 个字节开始到 offset + length 个字节为止
- 例:offset 为3,length为6,写入位置从第4个字节开始到第9个字节为止,包括第4个字节与第9个字节
encoding:可选,指定写入字符串时使用的编码格式,默认utf8
3.3 StringDecoder对象
- 先安装
npm i string_decoder
- 引入:
const StringDecoder = require('string_decoder).StringDecoder
- 创建对象:
const decoder = new StringDecoder([encoding]) 【默认utf8】
- 将
Buffer 对象中的数据转换为字符串:decoder.write(buffer),【参数:Buffer对象】,返回转换后的字符串
- 当需要将多个
Buffer 对象中的二进制数据转换为文字的场合
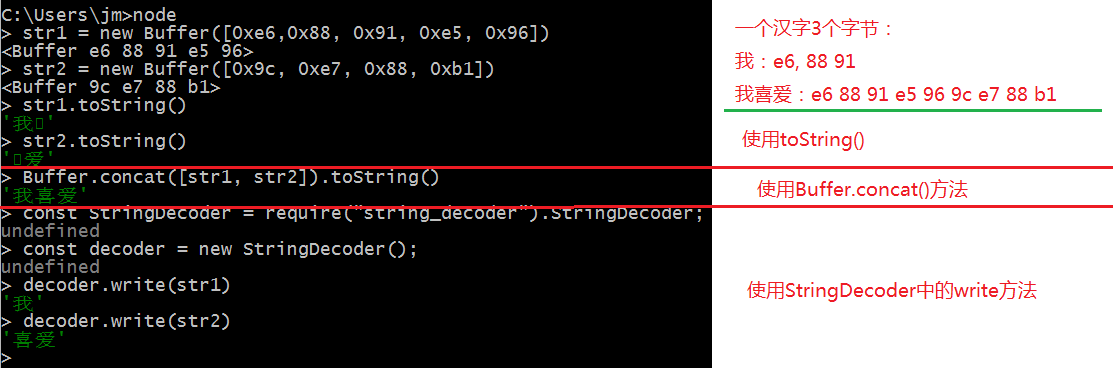
- 例:在
utf8编码格式中, “我喜爱” ==》 e6 88 91 e5 96 9c e7 88 b1,创建两个 Buffer,第一个存放前5字节数据,第二个存放后4字节数据。
- 使用
toString() 将两个 Buffer 对象转换为字符串,你会发现有乱码
- 可以通过
Buffer.concat() 方法,将两个Buffer对象拼接起来,再用toString() 转化
- 不过,当
Buffer 对象的长度较大,这种操作的性能将变得比较低下
- 使用
StringDecoder 对象的write 方法,可以正确将每个Buffer 对象中的数据正确转换为字符串
四、Buffer 对象与数值对象之间的转换
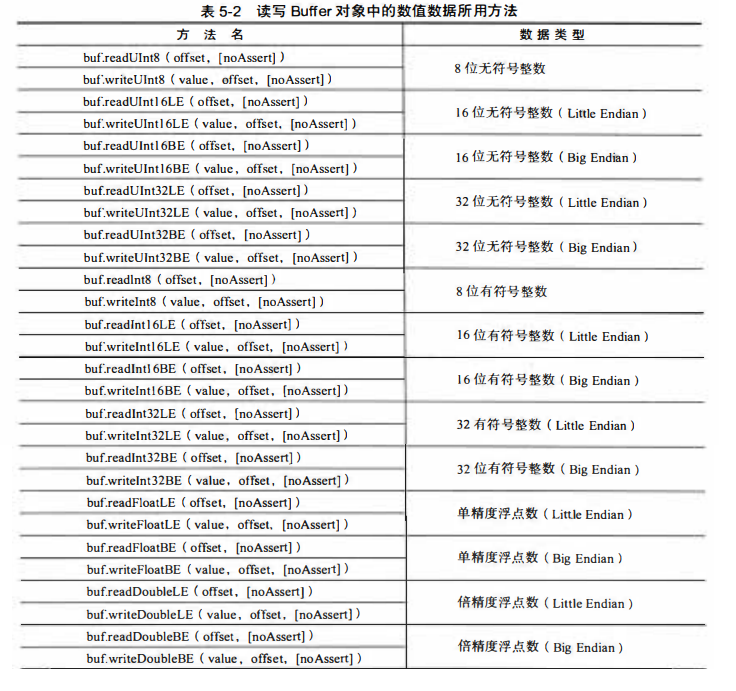
read 方法系列:将Buffer对象中的数读取为Number类型
- 第一个参数(
offset) :指定获取数据的起始位置,以字节为单位
- 第二个参数(
noAssert):可选,布尔类型,指定是否对offset的值进行验证。【默认false】
- 值为
false:如果offset参数值超出了缓存区的长度,则抛出 AssertionError 异常
- 值为
true:不抛出该异常
write 方法系列:将Number类型的数据转换为指定数据类型后写入到缓存区。
- 第一个参数 :必选,要写入的数据
- 第二个参数(
offset) :指定数据的起始写入位置,以字节为单位
- 第三个参数(
noAssert):可选,布尔类型,指定是否对offset的值进行验证。【默认false】
- 值为
false:如果offset参数值超出了缓存区的长度,则抛出 AssertionError 异常
- 值为
true:不抛出该异常
五、Buffer 对象与JSON对象之间的转换
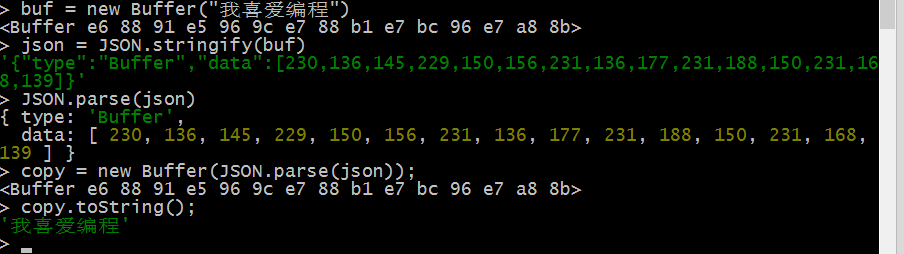
JSON.stringify():将Buffer对象中保存的数据转换为一个字符串JSON.parse():将一个经过转换后的字符串还原成一个数组
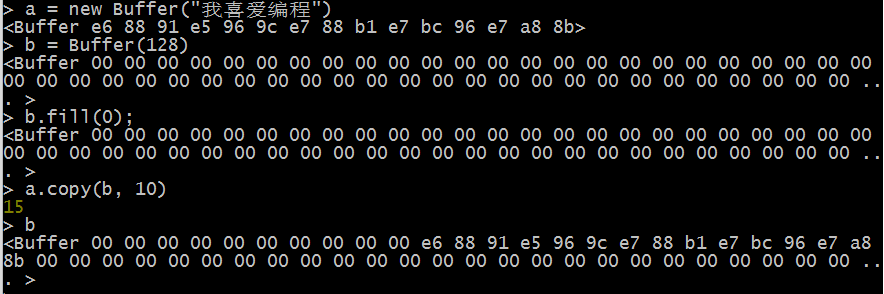
五、复制缓存数据
- 将
Buffer 对象中保存的二进制数据复制到另外一个 Buffer 对象中:buf.copy(targetBuffer, [targetStart], [sourceStart], [sourceEnd])
targetBuffer:必选,指定复制的目标 Buffer 对象targetStart:可选,指定目标Buffer对象中从第几个字节开始写入数据【参数值为一个小于目标Buffer对象长度的整数值,默认0】sourceStart:可选,从复制源Buffer对象中的第一个字节开始获取数据sourceEnd:可选,从复制源Buffer对象中获取数据时的结束位置,默认值为复制源Buffer对象的长度
六、Buffer类的方法
6.1 isBuffer()
Buffer.isBuffer(obj):判断一个对象是否为一个 Buffer 对象
6.2 byteLength()
Buffer.byteLength(string, [encoding]):计算一个指定字符串的字节数
6.3 concat()
Buffer.concat(list, [totalLength]):将几个Buffer 对象结合创建为一个新的Buffer对象
list:存放多个Buffer对象的数组totalLength:可选,指定被创建的Buffer对象的总长度,当省略该参数,被创建的Buffer对象为第一个参数数组中所有Buffer对象的长度的合计值
- 如果第一个参数值为空数组或第二个参数值等于 0, 那么
concat 方法返 回一个长度为 0的 Buffer 对象。
- 如果第一个参数值数组中只有一个
Buffer 对象, 那么 coneat 方法直接返回该 Buffer 对象。
- 如果第一个参数值数组中拥有一个以上的
Buffer 对象, 那么 coneat 方法返回被创建的 Buffer 对象。
6.4 isEncoding()
Buffer.isEncoding(str):检测一个字符串是否为一个有效的编码格式字符串
- 如果该字符串为有效的编码格式,返回
true
- 如果该字符串不是一个有效的编码格式,返回
false
对于本文内容有问题或建议的小伙伴,欢迎在文章底部留言交流讨论。