以下内容全部源于: 《JavaScript高级程序设计(第3版)》、《学习正则表达式》
一、RegExp 类型
1.1 RegExp 的表达方式
- 字面量
var expression = / pattern / flags ;
- 构造函数
var expression = new RegExp(pattern, flags);
- 构造函数里的
pattern和flags都是字符串的形式,如下:
var pattern2 = new RegExp("[bc]at", "i");
- 正则主要表达对字符串的一种过滤的逻辑。包括 匹配字符串 和 获取字符串。
1.2 模式(patterns)
- 模式(
pattern)部分可以是任何简单或复杂的正则表达式,可以包含字符类、限定符、分组、向前查找以及反向引用。
1.3 标志(flags)
- 每个正则表达式都可带有一或多个标志(
flags),用以标明正则表达式的行为。正则表达式的匹配模式支持下列3个标志。
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止;i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写;m:表示多行(multiline)模式,即在到达一行文本末尾时还会继续查找下一行中是否存在与模式匹配的项。
1.4 正则中的元字符
- 模式中使用的所有元字符都必须转义。正则表达式中的元字符包括:
( [ { \ ^ $ | ) ? * + .]}
注意:
- 传递给
RegExp构造函数的两个参数都是字符串(不能把正则表达式字面量传递给RegExp构造函数)。- 由于
RegExp构造函数的模式参数是字符串,所以在某些情况下要对字符进行双重转义。所有元字符都必须双重转义,那 些已经转义过的字符也是如此,例如\n(字符\在字符串中通常被转义为\\,而在正则表达式字符串中就会变成\\\\)。
- 下表给出了一些模式,左边是这些模式的字面量形式,右边是使用 RegExp 构造函数定义相同模式时使用的字符串。

1.5 RegExp实例属性
RegExp的每个实例都具有下列属性,通过这些属性可以取得有关模式的各种信息。
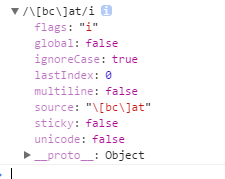
global:布尔值,表示是否设置了g标志。ignoreCase:布尔值,表示是否设置了i标志。lastIndex:整数,表示开始搜索下一个匹配项的字符位置,从0算起。multiline:布尔值,表示是否设置了m标志。source:正则表达式的字符串表示,按照字面量形式而非传入构造函数中的字符串模式返回。
var pattern1 = /\[bc\]at/i; // var pattern2 = new RegExp("\\[bc\\]at", "i");
alert(pattern1.global); //false
alert(pattern1.ignoreCase); //true
alert(pattern1.multiline); //false
alert(pattern1.lastIndex); //0
alert(pattern1.source); //"\[bc\]at"
- 下面是
console.dir出pattern2的属性。
1.6 RegExp构造函数属性
RegExp构造函数包含一些属性(这些属性在其他语言中被看成是静态属性)。- 这些属性适用于作用域中的所有正则表达式,并且基于所执行的最近一次正则表达式操作而变化。
- 关于这些属性的另一个独特之处,就是可以通过两种方式访问它们。
- 换句话说,这些属性分别有一个长属性名和一个短属性名(
Opera是例外,它不支持短属性名)。

- 使用这些属性可以从
exec()或test()执行的操作中提取出更具体的信息。请看下面的例子。
var text = "this has been a short summer";
var pattern = /(.)hort/g;
/*
* 注意:Opera 不支持 input、lastMatch、lastParen 和 multiline 属性
* Internet Explorer 不支持 multiline 属性
*/
if (pattern.test(text)){
alert(RegExp.input); // this has been a short summer
alert(RegExp.leftContext); // this has been a
alert(RegExp.rightContext); // summer
alert(RegExp.lastMatch); // short
alert(RegExp.lastParen); // s
alert(RegExp.multiline); // false
}
- 以上代码创建了一个模式,匹配任何一个字符后跟 hort,而且把第一个字符放在了一个捕获组中。
- RegExp 构造函数的各个属性返回了下列值:
input属性返回了原始字符串;leftContext属性返回了单词short之前的字符串,而rightContext属性则返回了 short之后的字符串;lastMatch属性返回最近一次与整个正则表达式匹配的字符串,即short;lastParen属性返回最近一次匹配的捕获组,即例子中的s。
- 如前所述,例子使用的长属性名都可以用相应的短属性名来代替。
- 只不过,由于这些短属性名大都不是有效的
ECMAScript标识符,因此必须通过方括号语法来访问它们,如下所示。
var text = "this has been a short summer";
var pattern = /(.)hort/g;
/*
* 注意:Opera 不支持 input、lastMatch、lastParen 和 multiline 属性
* Internet Explorer 不支持 multiline 属性
*/
if (pattern.test(text)){
alert(RegExp.$_); // this has been a short summer
alert(RegExp["$`"]); // this has been a
alert(RegExp["$'"]); // summer
alert(RegExp["$&"]); // short
alert(RegExp["$+"]); // s
alert(RegExp["$*"]); // false
}
- 除了上面介绍的几个属性之外,还有多达 9 个用于存储捕获组的构造函数属性。
- 访问这些属性的语法是
RegExp.$1、RegExp.$2…RegExp.$9,分别用于存储第一、第二……第九个匹配的捕获组。- 在调用
exec()或test()方法时,这些属性会被自动填充。- 然后,我们就可以像下面这样来使用它们。
var text = "this has been a short summer";
var pattern = /(..)or(.)/g;
if (pattern.test(text)){
alert(RegExp.$1); //sh
alert(RegExp.$2); //t
}
- 这里创建了一个包含两个捕获组的模式,并用该模式测试了一个字符串。
- 即使
test()方法只返回一个布尔值,但RegExp构造函数的属性$1和$2也会被匹配相应捕获组的字符串自动填充。
二、RegExp实例方法
2.1 exec()
- 该方法是专门为捕获组而设计的。
exec()接受一个参数,即要应用模式的字符串,然后返回包含第一个匹配项信息的数组;或者在没有匹配项的情况下返回null。
- 返回的数组虽然是
Array的实例,但包含两个额外的属性:index和input。
index表示匹配项在字符串中的位置input表示应用正则表达式的字符串。- 在数组中,第一项是与整个模式匹配的字符串,其他项是与模式中的捕获组匹配的字符串(如果模式中没有捕获组,则该数组只包含一项)。
String类型是字符串的对象包装类型。可使用String构造函数来创建。
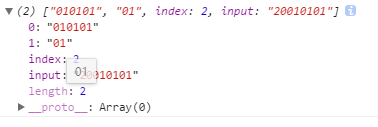
- 例1:没有捕获组的exec()
var re1 = /010101/.exec('20010101');
- 结果:

- 例2:有捕获组的exec()
var re2 = /(01){3}/.exec('20010101');
- 结果:
- 表面上看
re1和re2所表达的意思是一样的,但是re2多了捕获组,re1缺少了捕获组。- 数组中的第一项是匹配的整个字符串,第二项包含与第一个捕获组匹配的内容,第三项包含与第二个捕获组匹配的内容。
- 对于
exec()方法而言,即使在模式中设置了全局标志(g),它每次也只会返回一个匹配项。
- 在不设置全局标志的情况下,在同一个字符串上多次调用
exec()将始终返回第一个匹配项的信息。- 而在设置全局标志的情况下,每次调用
exec()则都会在字符串中继续查找新匹配项,如下面的例子所示。
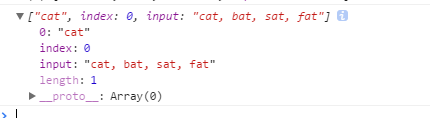
- 例3:不设置全局标志
var text = "cat, bat, sat, fat";
var pattern1 = /.at/;
var matches = pattern1.exec(text);
console.log(matches);
matches = pattern1.exec(text);
console.log(matches);
- 上述代码的两个
console.log输出的结果都是一样的,如下所示:
- 例4:设置全局标志
var text = "cat, bat, sat, fat";
var pattern2 = /.at/g;
var matches = pattern2.exec(text);
console.log(matches);
matches = pattern2.exec(text);
console.log(matches);
- 上述代码第一个
console.log输出的结果,如下所示:
- 上述代码第二个
console.log输出的结果,如下所示:

- 注意模式的
lastIndex属性的变化情况:
- 在全局匹配模式下,
lastIndex的值在每次调用exec()后都会增加- 在非全局模式下则始终保持不变。
2.2 test()
- 它接受一个字符串参数。在模式与该参数匹配的情况下返回
true;否则,返回false。
pattern.test(string);
RegExp实例继承的toLocaleString()和toString()方法都会返回正则表达式的字面量,与创建正则表达式的方式无关。
var pattern = new RegExp("\\[bc\\]at", "gi");
alert(pattern.toString()); // /\[bc\]at/gi
alert(pattern.toLocaleString()); // /\[bc\]at/gi
- 即使上例中的模式是通过调用
RegExp构造函数创建的,但toLocaleString()和toString()方法仍然会像它是以字面量形式创建的一样显示其字符串表示。
- 正则表达式的
valueOf()方法返回正则表达式本身。
test()方法经常被用在if语句中
var text = "000-00-0000";
var pattern = /\d{3}-\d{2}-\d{4}/;
if (pattern.test(text)){
alert("The pattern was matched.");
}
三、模式的局限性
- 尽管
ECMAScript中的正则表达式功能还是比较完备的,但仍然缺少某些语言(特别是Perl)所支持的高级正则表达式特性。- 下面列出了 ECMAScript 正则表达式不支持的特性(要了解更多相关信息,请访问
www.regular-expressions.info)。
- 匹配字符串开始和结尾的
\A和\Z锚- 向后查找(
lookbehind- 并集和交集类
- 原子组(
atomic grouping)-
Unicode支持(单个字符除外,如\uFFFF)- 命名的捕获组
s(single,单行)和x(free-spacing,无间隔)匹配模式- 条件匹配
- 正则表达式注释
四、pattern的相关知识
4.1 基本语法
[xyz]:一个字符集,匹配任意一个包含的字符[^xyz]:一个否定字符集,匹配任何未包含的字符\w:匹配字母或数字或下划线的字符\W:匹配不是字母、数字、下划线的字符\s:匹配任意空白字符\S:匹配不是空白符的字符\d:匹配数字\D:匹配非数字的字符\b:匹配单词的开始或结束的位置\B:匹配不是单词开头或结束的位置$:匹配字符串的开始^:匹配字符串的结束
4.2 重复(量词)
*:重复 0 次 或 多 次+:重复 1 次 或 多 次?:重复 0 次 或 1 次{n}:重复 n 次{n,}:重复 n 次 或 更多次{n,m}:重复 n 次到 m 次
4.3 分组和捕获
- 当一个模式的全部或者部分内容由一对括号分组时,它就对内容进行捕获并临时存储于内存中。
- 可以使用
RegExp.$num(num是整数,从1开始)来引用重用捕获的内容,但是只能获取最新一组的捕获组,并且是在调用对应的exec()方法的情况下才可以。例子如下所示
- 点击打开demo1
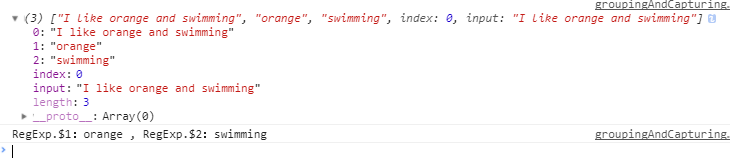
var pattern = /I like (apple|orange) and (swimming|running)/;
var test = pattern.exec('I like orange and swimming');
console.log(test);
console.log(RegExp.$1,RegExp.$2); // orange swimming
- 正向引用
- 点击打开demo2
var pattern = /I like (apple|orange) and (swimming|running)/;
var test = pattern.exec('I like orange and swimming');
var test2 = pattern.exec('I like apple and running'); // 如果注释了这里,那么下面的输出依然是orange swimming
console.log(test);
console.log(test2);
console.log('RegExp.$1:' + RegExp.$1,',RegExp.$2:' + RegExp.$2); // RegExp.$1:apple ,RegExp.$2:running
// 上面这一行代码相当于获取的是 test2 的的捕获组,因此 test[1] 等价于 RegExp.$1
- 再次提醒:在
RegExp上将会存储最近的一次捕获,并且是从$1开始,$0是undefined。
- 反向引用,通过分组和
\n(n从1开始) 来实现反向引用。 例子如下:匹配一个div元素- 点击打开demo
// 这个写法错误:var reg = /<(div)><\/$1>/;
var reg = /<(div)><\/\1>/; // 等价于 /<div></div>/
console.log(reg.test('<div></div>')); //true
4.4 非捕获分组
- 非捕获分组不会将其内容存储在内存中。
- 在你并不想引用分组的时候,可以使用它。
- 由于不存储内容,非捕获分组就会带来较高的性能。
(the|The|THE)
//你不需要任何后向引用,因此可以这样写一个非捕获分组:
(?:the|The|THE)
// 可以添加选项将其变为不区分大小写的模式,就像这样:
(?i)(?:the)
// 或者你也可以这样做
(?:(?i)the)
// 下面这种写法最值得推荐:该选项 i 可以放在问号和冒号之间。
(?i:the)
- 示例:我只想捕获我喜欢的水果,但不想捕获我喜欢做什么运动。
- 点击打开demo
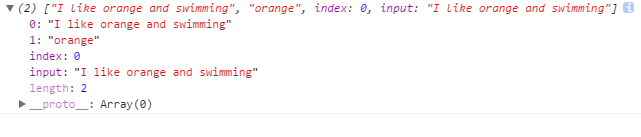
var pattern = /I like (apple|orange) and (?:swimming|running)/;
var test = pattern.exec('I like orange and swimming');
console.log(test);
- 结果:并没有
swimming和running的捕获分组
4.5 贪心、懒惰与占有
- 贪心
- 量词自身是贪心的。贪心的量词会首先匹配整个字符串。尝试匹配时,它会选定尽可能多的内容,也就是整个输入。
- 量词首次尝试匹配整个字符串,如果失败则回退一个字符后再次尝试。
- 这个过程叫做回溯(
backtracking)。
- 它会每次回退一个字符,直到找到匹配的内容或者没有字符可尝试为止。
- 此外,它还记录所有的行为,因此相较另两种方式它对资源的消耗最大。
- 它先“吃”尽所有的字符,然后每次“吐”出一点,慢慢咀嚼消化……你应该明白了。
- 以下量词都起到贪婪匹配的作用。

- 看一个例子:
- 点击打开demo
var str = '<span>hello</span><span>world</span>';
var reg = /<span>.*<\/span>/;
console.log(reg.exec(str));
- 结果如下。你会发现全部
span都匹配了。- 其实这个正则是没有问题的,因为第一个
<span>和最后一个</span>也可以凑成一对。- 实质上:是由于
.*的贪婪性所导致的,只要符合匹配规则的字符串都会全部匹配。

- 现在我只想匹配一个
span,此时就要引入另外一个概念:惰性匹配。
- 懒惰
- 懒惰(有时也说勉强)的量词则使用另一种策略。
- 它从目标的起始位置开始尝试寻找匹配,每次检查字符串的一个字符,寻找它要匹配的内容。
- 最后,它会尝试匹配整个字符串。
- 要使一个量词成为懒惰的,必须在普通量词后添加一个问号(
?)。- 它每次只“吃”一点。
- 以下是惰性量词:

- 例1:只匹配一个
span- 点击打开demo
var str = '<span>hello</span><span>world</span>';
var reg = /<span>.*?<\/span>/;
console.log(reg.exec(str));
- 结果如下:

- 占有量词
- 占有量词会覆盖整个目标然后尝试寻找匹配内容,但它只尝试一次,不会回溯。
- 占有量词就是在普通量词之后添加一个加号(+)。
- 它不“咀嚼”而是直接“吞咽”,然后才想知道“吃”的是什么。

4.6 正向前瞻和后向前瞻
- 正向前瞻(
look ahead positive assert)——?=
- 要匹配某个模式时,需要在它后面找到含有给定前瞻模式的内容。
- 如:
/Lily(?=love swimming)/,即:匹配后面跟随的是love swimming的Lily。
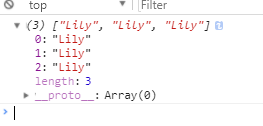
- 例子:点击打开demo
var pattern = /Lily(?=\slike\sswimming)/g;
var target = 'Lily like swimming Lily like swimming Lily like swimming ';
console.log(target.match(pattern)); // ["Lily", "Lily", "Lily"]
- 结果如下:
- 后向前瞻(
look ahead negative assert)——?!
- 要匹配某个模式时,需要在它后面找不到含有给定前瞻模式的内容。
- 如:
/Lily(?!love swimming)/,即:匹配后面跟随的不是love swimming的Lily。
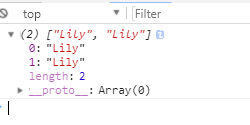
- 例子:点击打开demo
var pattern = /Lily(?=\slike\sswimming)/g;
var target = 'Lily like swimming Lily like swimming Lily like running ';
console.log(target.match(pattern)); // ["Lily", "Lily"]
- 结果如下:
- tips: 如果我们遇到空格的情况下,尽量使用
\s。